在当今的数字化时代,AI与网络内容的交互模式正经历着深刻变革,这其中Cloudflare推出的Pay Per Crawl举措极具标志性意义。
AI巨头「白嫖」模式的历史成因与崩塌
1. 搜索时代「流量-广告」隐形契约的运作逻辑
在过去的搜索时代,存在着一种隐形契约。多数网页默认公开可被搜索引擎爬虫抓取,像谷歌、Bing这类搜索引擎,它们通过抓取网页内容,为网站带来流量。网站则凭借这些流量,通过投放广告或者销售订阅等方式实现变现。这种模式下,网站内容与流量、广告收益紧密相连,形成了一个相对稳定的运作逻辑,各方在这个生态中各取所需,维持着一种看似平衡的状态。
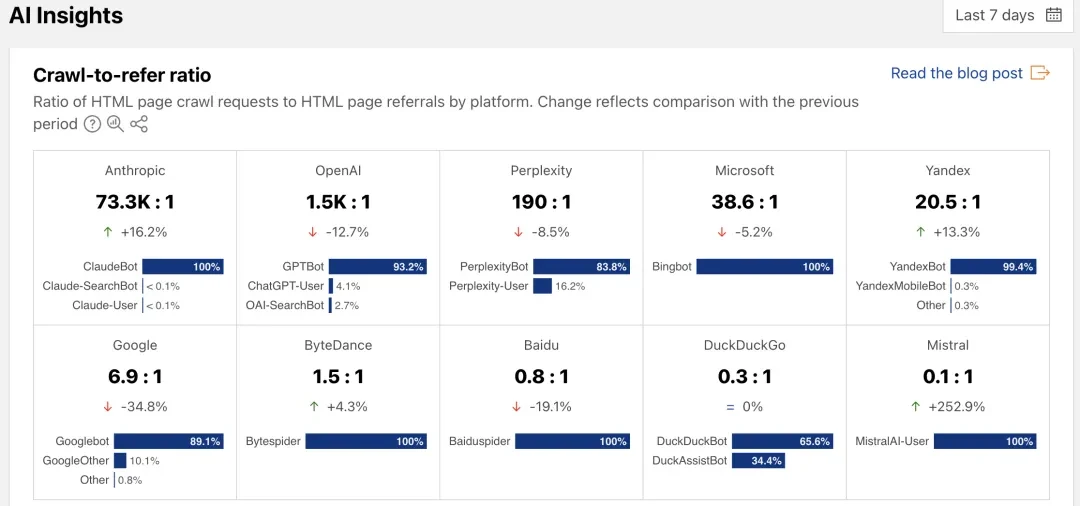
2. AI大模型训练对传统流量模式的颠覆
然而,随着AI时代的到来,情况发生了巨大变化。AI公司将全网内容视作训练大模型的燃料,大量抓取网站数据。但与传统搜索引擎不同的是,当用户直接在AI聊天机器人中提问时,答案往往是对相关内容的总结呈现,并非像以往那样通过提供数十个蓝色链接引导用户点击进入网站,这就导致网站获得的流量大幅减少。例如谷歌这样的搜索巨头自身业务也在转变,其在搜索页面推出“人工智能概述”,据报告显示,75%的查询用户无需点击任何链接就能得到解答。如此一来,传统的“内容换流量”模式逐渐失效,AI巨头们大量消耗网站内容却未给网站带来相应的流量导流,使得内容生产者面临愈发艰难的处境。
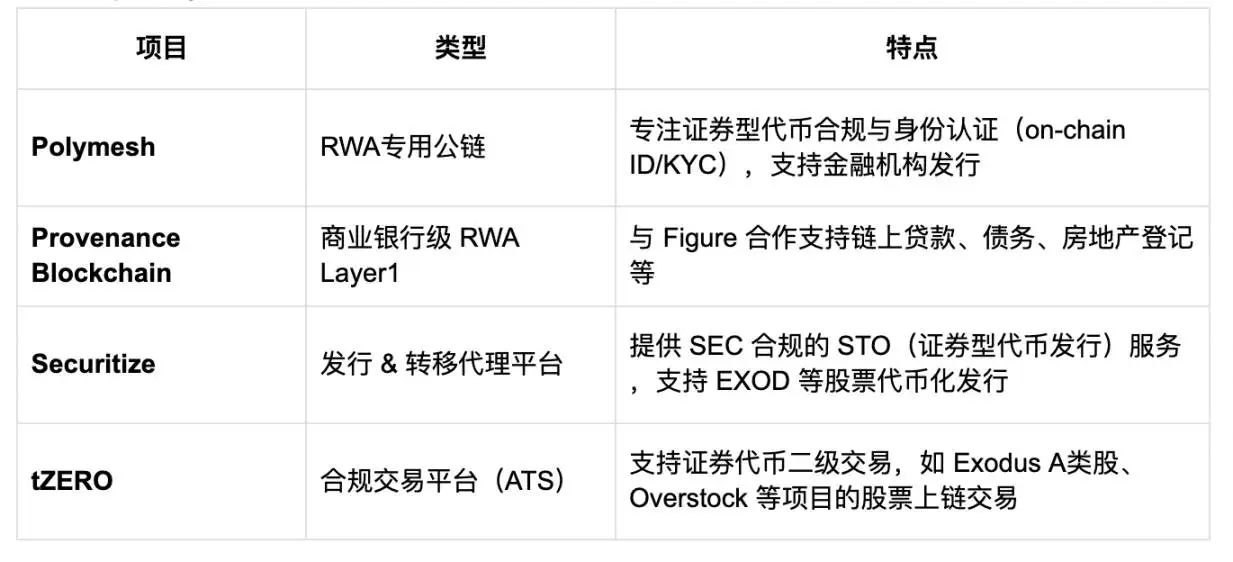
3. 数据失衡:从谷歌7次抓取1次点击到Anthropic7万次抓取1次跳转的演变
从数据层面来看,这种失衡愈发明显。Cloudflare在2025年7月的最新数据表明,谷歌的爬虫大约每6至7次抓取能给网站带回1次点击,而OpenAI则需1500次抓取才换来1次跳转,Anthropic的情况更为夸张,高达73300次抓取才换来1次跳转。这清晰地展现出随着从传统搜索到AI应用的发展,网站从爬虫抓取中获得有效反馈(如点击、跳转等)的比例急剧下降,数据获取与回馈之间的失衡不断加剧,进一步凸显了AI巨头“白嫖”模式下内容创作者所面临的困境以及传统流量模式被颠覆后的严峻现状。
Pay Per Crawl机制的技术实现解析
1. 权限控制系统:允许/收费/封锁三重选择
在Pay Per Crawl机制中,权限控制系统起着关键作用。Cloudflare为网站提供了三种针对AI爬虫的权限设置选项,即允许、收费、封锁。新加入Cloudflare的网站默认封锁AI爬虫,除非站长主动进行其他设置。站长可依据自身需求在后台灵活选择。这一设计赋予了网站内容创作者充分的自主权,使其能根据自身利益和对AI爬虫的态度来决定是否允许其访问以及是否收取费用。例如,对于一些希望借助AI提升曝光度的创作者,可能会选择允许访问;而对于担心数据被过度利用且希望获得经济回报的创作者,则可选择收费模式;若创作者不愿其内容被AI爬虫抓取,便可直接选择封锁。这种三重选择的权限控制系统改变了以往AI爬虫随意抓取网站内容的局面,将控制权交回到了内容创作者手中。
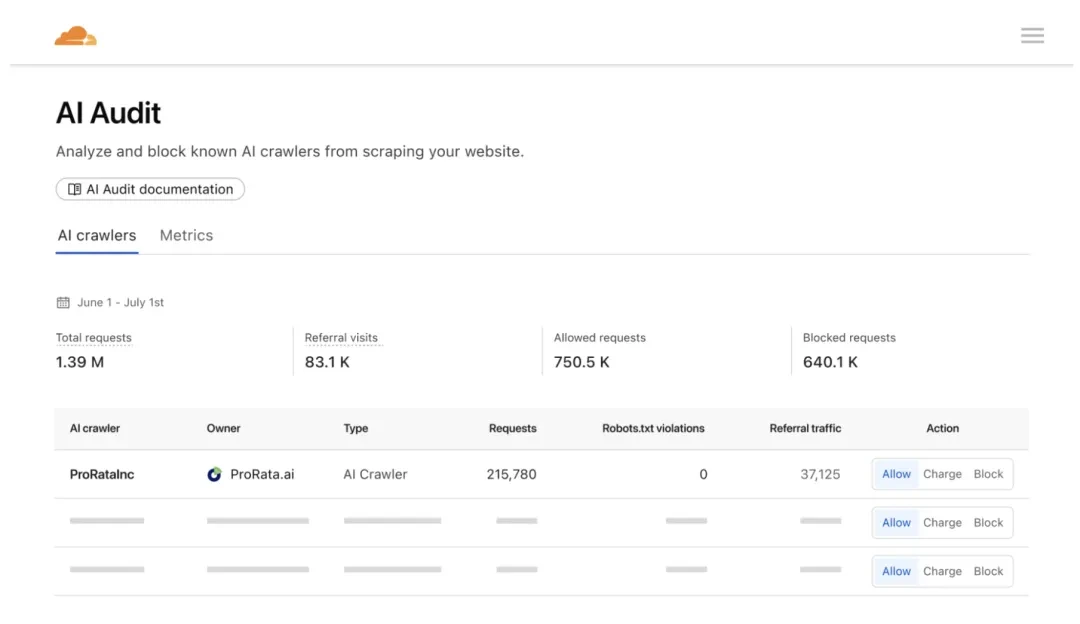
▌Pay Per Crawl支付流程与访问控制图示


2. 基于HTTP 402状态码的支付协议
Cloudflare在Pay Per Crawl机制里采用了基于HTTP 402状态码的支付协议。当AI爬虫向付费URL发起请求但尚未付费时,Cloudflare会返回HTTP 402 Payment Required状态码。此状态码是专门为“网络支付”预留的,过去鲜少被使用。AI爬虫可在请求里带上支付信息,以表示同意支付配置的价格,一旦价格匹配成功,便会放行并返回200 OK状态码,同时自动完成结算流程。Cloudflare在这一过程中充当着“收银台”的角色,负责聚合账单以及分发收益。这种支付协议通过标准化的状态码交互,确保了AI爬虫付费过程的规范化和自动化,为实现按次付费爬取的经济交易提供了可靠的技术支撑。

3. 数字签名验证体系与防作弊机制
为防止“山寨爬虫”冒充合规者逃避支付等作弊行为,Pay Per Crawl机制构建了数字签名验证体系。Cloudflare要求AI公司注册密钥,利用数字签名来保证其身份的真实性和合法性。这意味着,只有经过合法注册且拥有有效数字签名的AI爬虫才能参与到付费爬取流程中。通过这种方式,有效杜绝了未经授权或恶意的爬虫绕过支付环节获取网站内容的可能性,维护了付费爬取市场的公平性和正常秩序,保障了内容创作者和合法AI公司的权益。
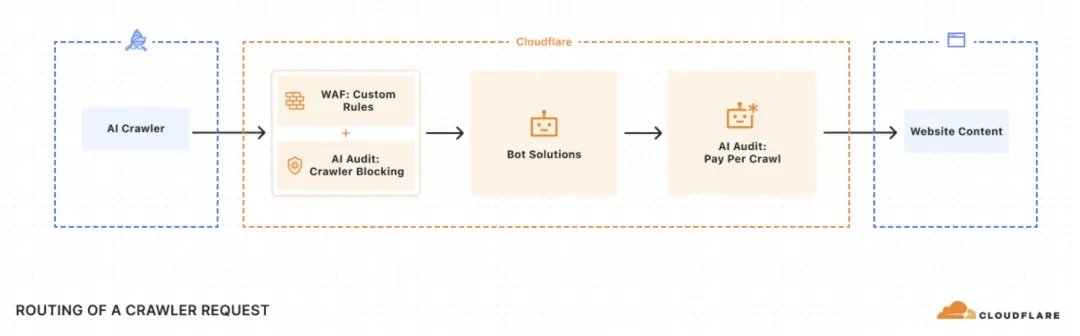
4. CDN中间层流量处理技术架构
Pay Per Crawl机制建立在Cloudflare全球CDN网络的中间层。凭借其在全球300多个城市部署的节点,承载着约20%的Web流量这一优势,Cloudflare能够在访问请求进到源站前就精准地识别和处理AI爬虫。这一CDN中间层流量处理技术架构使得网站内容的访问控制和付费爬取管理更加高效和便捷。它可以在不影响正常用户访问网站的前提下,对AI爬虫的请求进行针对性处理,无论是根据权限设置进行允许、收费还是封锁操作,都能在这一中间层快速且准确地完成,从而为Pay Per Crawl机制的整体运行提供了坚实的技术基础。
新型付费模式的双重影响分析
1. 内容创作者的收益提升:从广告依赖到直接授权变现
在传统模式下,内容创作者主要依赖广告来实现网站流量的变现。然而,随着AI时代的到来,AI巨头的爬虫大量抓取内容,却未能给创作者带来与之匹配的流量回报,使得传统的“内容换流量,再通过广告变现”模式难以为继。Cloudflare推出的“Pay Per Crawl”机制为内容创作者提供了新的变现途径。通过该机制,创作者可在后台选择对AI爬虫的访问权限,如允许、收费或封锁。当选择收费模式时,AI爬虫每次抓取内容都需付费,这使得创作者能够直接从内容授权中获得收益,不再单纯依赖广告收入,从而提升了收益的稳定性和可预期性。
2. AI公司的成本重构:数据采购支出与合规优化
对于AI公司而言,“Pay Per Crawl”模式带来了成本结构的重大变化。以往,它们可以近乎免费地抓取全网内容用于模型训练,如今则需为获取数据支付相应费用,这无疑增加了数据采购支出这一成本要素。但与此同时,这种付费模式也带来了一定的优势。通过明码标价的付费获取数据,AI公司能够有效避免因未经授权抓取数据而引发的版权争议问题,实现了数据获取的合规化,从长远来看有助于公司的稳健发展。
3. 中小网站议价权崛起与生态格局变化
过去,只有头部大媒体具备与AI公司谈授权的能力,绝大多数中小网站在面对AI爬虫的肆意抓取时,往往毫无议价能力,甚至缺乏相关意识。而“Pay Per Crawl”机制的出现,赋予了中小网站自主选择是否允许AI爬虫访问以及是否收费的权利,使得它们在数据使用的谈判桌上拥有了一席之地,议价权得以崛起。这一变化将对整个互联网生态格局产生影响,有望促使数据使用更加公平、合理,推动整个行业朝着更加健康、有序的方向发展。
实施挑战与行业争议焦点
1. 技术层面:山寨爬虫识别与支付系统标准化难题
在当前的网络环境下,随着“Pay Per Crawl”机制的出现,技术层面面临着诸多挑战。一方面,山寨爬虫的识别成为难题。一些不法分子可能会试图绕过付费机制,通过模仿正规AI爬虫的行为来获取数据而不支付费用。Cloudflare虽要求AI公司注册密钥并用数字签名保证身份,但仍难以完全杜绝此类现象。因为网络环境复杂,技术手段不断更新,山寨爬虫的伪装方式也可能日益复杂,给准确识别带来困难。
另一方面,支付系统标准化尚未完善。虽然Cloudflare建立了基于自身的权限和支付系统,通过如返回HTTP 402 Payment Required状态码等方式来规范支付流程,但整个行业内缺乏统一的支付系统标准。不同的内容平台、AI公司可能采用不同的支付方式和技术架构,这在跨平台、跨公司的数据交互中容易产生兼容性问题,阻碍了“Pay Per Crawl”模式的广泛推广和高效运行。
2. 经济层面:中小型AI团队的数据获取困境
从经济角度来看,“Pay Per Crawl”模式给中小型AI团队带来了数据获取方面的困境。对于这些团队而言,资金相对有限,而购买数据的成本成为了一项沉重负担。以往可以免费获取的大量网络数据,如今需要付费才能使用,使得他们在数据资源的获取上受到限制。
与大型AI公司相比,中小型团队没有足够的财力去大规模采购高价值的数据内容,这可能导致他们在模型训练等方面的数据量不足,进而影响其AI产品的质量和竞争力。而且,在数据市场的议价过程中,由于规模和资金的劣势,他们也难以获得像大型公司那样优惠的价格和良好的合作条件,进一步加剧了其在数据获取上的困境。
3. 伦理层面:知识开放性与商业化的平衡争议
在伦理层面,“Pay Per Crawl”模式引发了关于知识开放性与商业化平衡的争议。一方面,内容创作者认为通过对AI爬虫的付费限制,可以保障自身的权益,使其劳动成果得到应有的经济回报,这是一种合理的商业化体现。然而,另一方面,这也可能在一定程度上限制了知识的开放性传播。
例如,对于一些学术研究、公益存档等“良性爬虫”行为,可能会因为付费门槛而受到阻碍,导致这些原本旨在促进知识共享和学术交流的活动难以顺利开展。如何在保障内容创作者经济利益的同时,又不阻碍知识在合理范围内的自由传播,成为了亟待解决的伦理难题,需要在商业化和知识开放性之间找到一个恰当的平衡点。
4. 垄断风险:数据付费是否会加剧行业马太效应
数据付费模式的推行还引发了关于垄断风险的担忧,即是否会加剧行业的马太效应。大型AI公司通常拥有雄厚的资金实力,在数据付费时代,他们更有能力购买大量优质的数据资源,从而进一步提升其AI产品的性能和竞争力。
而对于中小型企业和新兴的AI创业团队来说,由于难以承担高昂的数据采购费用,可能会在竞争中逐渐落后。长此以往,行业内的资源可能会越来越集中于少数大型公司手中,形成垄断局面,抑制整个行业的创新活力,使得数据付费模式在推动行业发展的同时,也可能带来不利于行业多元化和创新发展的潜在风险。
未来演进路径与产业变革预测
1. 动态定价机制探索:内容价值评估体系的构建
随着相关机制的发展,动态定价机制的探索成为重要方向。未来可能会构建起更为完善的内容价值评估体系,不再单纯以流量衡量内容价值。比如,出版商或其他机构可针对不同内容类型收取不同费用,还能依据AI应用的用户数量进行动态定价,或者按照训练、推理、搜索等不同领域引入更细粒度的定价策略。如此一来,能更精准地反映内容在AI时代的真实价值,推动产业向更合理的价值分配模式发展。
2. 智能代理经济生态的延伸可能性
按次付费爬虫的潜力有望在智能代理的世界中充分显现。设想智能代理付费墙能以程序化方式运作,用户可给智能代理设定预算,用于获取最有用、最相关的内容。这将开启智能代理以程序化方式协商访问数字资源的未来,极大地延伸智能代理经济生态,为内容获取与使用创造新的模式与场景。
3. 其他CDN服务商的跟进预期
目前,像Akamai、Fastly、Amazon CloudFront等其他CDN和安全提供商尚未宣布类似功能。但鉴于Cloudflare此次举措在解决AI与内容创作者利益冲突等方面的潜在影响,未来不排除其他CDN服务商跟进的可能。一旦有更多服务商加入,将进一步改变行业格局,促使整个行业在数据获取与付费等方面形成更规范、更广泛的机制。

4. 互联网商业模式的根本性重构
AI时代的到来促使互联网商业模式面临根本性重构。以往搜索时代靠流量转化广告收益的模式,在AI大模型训练对传统流量模式的颠覆下难以为继。如今,如“Pay Per Crawl”这类机制的出现,使得内容从“广告变现”走向“内容授权变现”成为可能,赋予了内容创作者更多议价权,也让AI公司在数据获取上需付出相应成本。这一系列变化正推动互联网商业模式朝着更注重内容价值、更强调数据付费与授权的方向进行深度重构。